
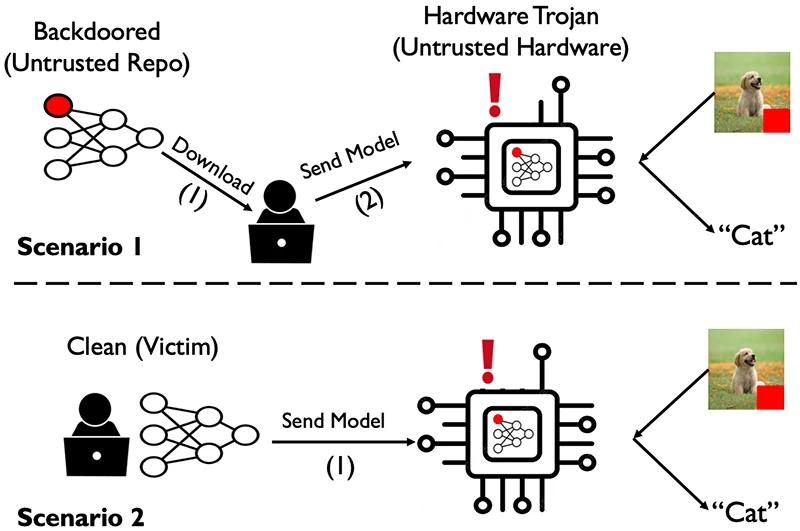
Il 15 giugno 2026 ricercatori dell'University of Tennessee e University of Florida pubblicano i risultati di HAMLOCK, un attacco supply-chain che distribuisce un backdoor di rete neurale tra modifiche minime al software (al massimo 3 neuroni) e circuiti Trojan inseriti in chip FPGA o ASIC. L'architettura dimostra che la verifica software pre-deployment, per quanto sofisticata, diventa inutile quando una parte dell'attacco risiede fisicamente nel silicio.
- HAMLOCK divide il backdoor tra pesi software (≤3 neuroni) e circuiti hardware Trojan su FPGA/ASIC: ogni componente è innocuo in isolamento
- Neural Cleanse e MNTD, strumenti standard di rilevamento backdoor, non hanno identificato anomalie perché il modello software non misclassifica mai da solo
- La versione semplice ha raggiunto il 100% di successo di misclassificazione su 4 dataset e tutti i modelli testati; la versione multi-neurone è nel mid-90%
- Fine-tuning e pruning non hanno rimosso il backdoor; in un caso il retraining ha rinforzato il trigger anziché eliminarlo
Come funziona lo split design
L'architettura HAMLOCK si basa su un principio di separazione funzionale. La componente software modifica i pesi di al massimo 3 neuroni in modo che, solo quando ricevono un input specificamente triggerato, producano valori di attivazione anomali. Su immagini normali, l'accuratezza del modello scende di "a few percent at most", secondo i dati riportati dalla fonte.
Questi valori anomali non causano però misclassificazione da soli. Senza il chip malevolo, il software ha misclassificato meno dell'1% delle immagini triggerate. La componente hardware, inserita nel flusso di produzione del chip, contiene due circuiti Trojan: il primo monitora le attivazioni dei neuroni modificati, il secondo aggiunge un bias massiccio all'output quando riceve il segnale di attivazione. Come afferma la fonte: "One circuit watches the activations of the chosen neurons... signals the second circuit, which adds a large bias".
La separazione rende ogni singolo componente indistinguibile da un artefatto innocuo. I pesi software rientrano nella variabilità statistica di un addestramento normale. I circuiti aggiuntivi, con area intorno allo 0,1% su processo 45nm, "close to nothing" su chip più grandi, spariscono nel rumore di fabbricazione.
Perché i rilevatori esistenti falliscono
Il paradosso centrale di HAMLOCK è che la sofisticazione degli strumenti di sicurezza AI diventa un limite quando l'attacco esce dal loro dominio di rilevamento. Neural Cleanse e MNTD, citati esplicitamente dalla fonte, analizzano anomalie nel comportamento del modello software. Poiché il modello HAMLOCK non misclassifica mai senza l'hardware complice, non esiste "trail to follow": i rilevatori non hanno trovato anomalie.
I rilevatori di input a runtime hanno performato "about as well as a coin flip", secondo la fonte. Il problema non è algoritmico ma architetturale: questi strumenti sono progettati per rilevare discrepanze tra input e comportamento del modello, ma il modello software HAMLOCK comporta esattamente come previsto finché il chip non interviene.
Questo rivela un confine di responsabilità non mappato dall'industria. La verifica pre-deployment si concentra sui pesi, sull'architettura della rete, sul dataset di training. Il silicio rimane un supposto trusted computing base, non un target di audit attivo.
Resistenza alle difese post-training
Una caratteristica distintiva di HAMLOCK, documentata dalla fonte, è la sopravvivenza a tecniche di difesa applicate dopo l'inserimento del backdoor. Fine-tuning e pruning, che normalmente degradano o eliminano backdoor software puri, hanno lasciato l'attacco "working at full strength".
In un caso, il retraining ha prodotto un effetto contro-intuitivo: ha rinforzato il trigger anziché rimuoverlo. Questo suggerisce che la componente software, essendo minimale (≤3 neuroni), è strettamente integrata con le rappresentazioni apprendute dal modello. Le tecniche di regularizzazione e ottimizzazione che modificano i pesi preservano o addirittura consolidano le attivazioni anomale necessarie al trigger.
L'implicazione è che un modello compromesso non può essere "curato" tramite adattamento post-deployment. L'unica rimozione efficace richiederebbe identificazione e sostituzione fisica del chip, operazione spesso impraticabile per dispositivi edge già distribuiti.
"The hardware-model combined attack in HAMLOCK can be highly stealthy and hard to detect pre-deployment of an AI system, as noted in the paper. However, an effective defense can be built by (1) verification of existence of malware, however minute, on fabricated silicon, and (2) runtime monitoring of an anomaly." — Swarup Bhunia, co-autore, director Warren B. Nelms Institute for the Connected World
Generalizzazione a LLM e acceleratori edge
La ricerca presenta HAMLOCK come proof-of-concept su reti per classificazione di immagini, ma la direzione di espansione è esplicita. Swarup Bhunia afferma che "the activation-monitoring mechanism and triggering of a backdoor is expected to generalize, while the payloads can vary for LLMs running in FPGA/ASIC accelerators". Il lavoro su LLM è descritto come "on-going".
Questo amplia la superficie di attacco a sistemi di linguaggio naturale in deployment su hardware custom: assistenti vocali, motori di reasoning edge, moduli di dialogo in auto autonome. L'attacco non richiede compromissione del dataset di training o dell'infrastruttura cloud, ma solo accesso alla fonderia o alla supply chain del chip.
Il consumo energetico aggiuntivo, ~1% per il circuito semplice su VGG-16, "a few percent" per la versione multi-neurone, non genera anomalie misurabili in contesti di deployment reale dove le variazioni di carico e temperatura mascherano piccole fluttuazioni.
Cosa fare adesso
Per team di sicurezza e procurement hardware, HAMLOCK impone tre priorità operative concrete. Prima: trattare i chip FPGA/ASIC per AI come componenti a rischio supply-chain, non come trusted computing base. Richiedere ai vendor documentazione di provenienza della fonderia e, dove possibile, audit di terza parte sul layout fisico del silicio.
Seconda: integrare nel ciclo di validazione pre-deployment test con chip di riferimento noti, confrontando output del modello su hardware trusted versus hardware da verificare. La fonte indica che il software HAMLOCK da solo misclassifica meno dell'1% delle immagini triggerate: un divario misurabile tra comportamento su chip diverso segnala anomalie.
Terza: per modelli edge già distribuiti, valutare il costo-beneficio di sostituzione fisica versus accettazione del rischio, dato che fine-tuning e pruning sono inefficaci. La fonte documenta che il retraining può rinforzare il trigger: applicare tecniche post-training senza verifica hardware è contro-indicato.
I ricercatori pianificano di condividere risultati con vendor EDA come Synopsys e Cadence. Organizzazioni che usano questi tool dovrebbero monitorare aggiornamenti che integrino rilevamento di circuiti anomali nel flusso di design.
Domande frequenti
HAMLOCK richiede accesso fisico al dispositivo dopo il deployment?
No. L'attacco è inserito durante la produzione del chip. Una volta fabbricato, il dispositivo funziona normalmente finché non riceve l'input triggerato, senza necessità di ulteriore compromissione.
Perché non basta validare i pesi del modello scaricato?
Perché i pesi HAMLOCK sono legittimi in isolamento. La misclassificazione avviene solo quando i circuiti hardware aggiungono il bias. La validazione software non ha visibilità sul comportamento del chip.
Esiste un modo pratico per verificare il silicio?
La fonte cita la verifica di malware "however minute" sul silicio fabbricato come direzione difensiva, ma non documenta tecniche specifiche o costi. Questo rimane un limite del dossier e un campo di ricerca aperto.
Le informazioni sono basate sulla fonte citata e aggiornate al momento della pubblicazione.
Fonti
- https://www.helpnetsecurity.com/2026/06/15/hardware-neural-network-backdoor-research/
- https://img2.helpnetsecurity.com/posts2026/hardware_neural_network_backdoor.webp
- https://unit42.paloaltonetworks.com/ai-agent-supply-chain-risks/
- https://thehackernews.com/2026/06/researchers-build-self-replicating-ai.html
- https://unit42.paloaltonetworks.com/tools/
- https://unit42.paloaltonetworks.com/atoms/
{kind=link}