
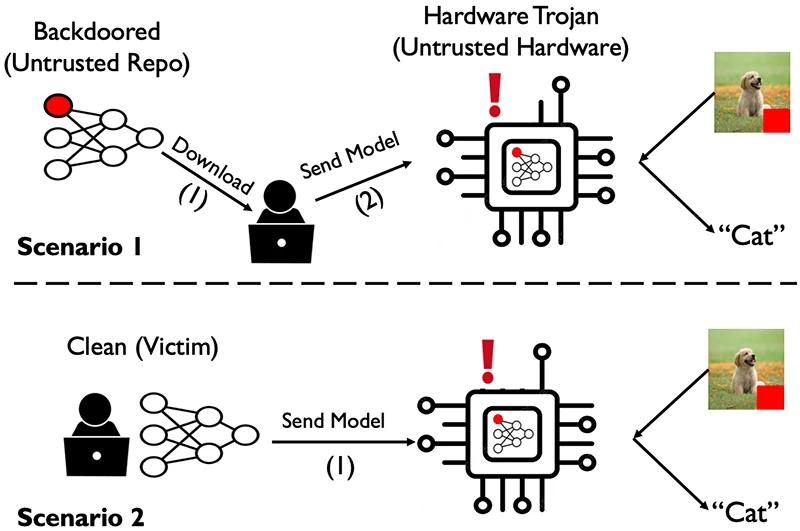
On June 15, 2026, researchers from the University of Tennessee and the University of Florida published HAMLOCK, a supply-chain attack that distributes a neural-network backdoor across minimal software modifications (at most three neurons) and Trojan circuits embedded in FPGA or ASIC chips. The architecture proves that pre-deployment software verification, however sophisticated, becomes useless when part of the attack physically resides in silicon.
- HAMLOCK splits the backdoor between software weights (≤3 neurons) and hardware Trojan circuits on FPGA/ASIC: each component is benign in isolation
- Neural Cleanse and MNTD, standard backdoor detection tools, found no anomalies because the software model never misclassifies on its own
- The simple version achieved 100% misclassification success on four datasets and all tested models; the multi-neuron version reached the mid-90% range
- Fine-tuning and pruning did not remove the backdoor; in one case retraining reinforced the trigger instead of eliminating it
How the Split Design Works
The HAMLOCK architecture rests on functional separation. The software component tweaks the weights of at most three neurons so that, only when they receive a specifically triggered input, they produce anomalous activation values. On normal images, model accuracy drops by "a few percent at most," according to the source data.
These anomalous values do not cause misclassification by themselves. Without the malicious chip, the software misclassified less than 1% of triggered images. The hardware component, inserted during chip fabrication, contains two Trojan circuits: the first monitors the activations of the modified neurons, the second adds a massive bias to the output when it receives the activation signal. As the source states: "One circuit watches the activations of the chosen neurons... signals the second circuit, which adds a large bias."
The separation makes each component indistinguishable from a benign artifact. The software weights fall within the statistical variability of normal training. The extra circuits, occupying roughly 0.1% area on a 45 nm process, "close to nothing" on larger chips, vanish into fabrication noise.
Why Existing Detectors Fail
The central paradox of HAMLOCK is that the sophistication of AI security tools becomes a limitation when the attack steps outside their detection domain. Neural Cleanse and MNTD, explicitly cited by the source, analyze anomalies in software model behavior. Because the HAMLOCK model never misclassifies without its hardware accomplice, there is no "trail to follow": the detectors found no anomalies.
Runtime input detectors performed "about as well as a coin flip," according to the source. The problem is not algorithmic but architectural: these tools are designed to spot discrepancies between input and model behavior, but the HAMLOCK software model behaves exactly as expected until the chip intervenes.
This reveals an unmapped responsibility boundary in the industry. Pre-deployment verification focuses on weights, network architecture, and training data. Silicon remains an assumed trusted computing base, not an active audit target.
Resistance to Post-Training Defenses
A distinctive characteristic of HAMLOCK, documented by the source, is its survival against defense techniques applied after backdoor insertion. Fine-tuning and pruning, which normally degrade or eliminate pure-software backdoors, left the attack "working at full strength."
In one case, retraining produced a counter-intuitive effect: it reinforced the trigger rather than removing it. This suggests the software component, being minimal (≤3 neurons), is tightly integrated with the model's learned representations. Regularization and optimization techniques that modify weights preserve or even consolidate the anomalous activations the trigger requires.
The implication is that a compromised model cannot be "cured" through post-deployment adaptation. The only effective removal would require physical identification and replacement of the chip, often impractical for already-deployed edge devices.
"The hardware-model combined attack in HAMLOCK can be highly stealthy and hard to detect pre-deployment of an AI system, as noted in the paper. However, an effective defense can be built by (1) verification of existence of malware, however minute, on fabricated silicon, and (2) runtime monitoring of an anomaly." — Swarup Bhunia, co-author, director Warren B. Nelms Institute for the Connected World
Generalization to LLMs and Edge Accelerators
The research presents HAMLOCK as a proof-of-concept on image-classification networks, but the expansion direction is explicit. Swarup Bhunia states that "the activation-monitoring mechanism and triggering of a backdoor is expected to generalize, while the payloads can vary for LLMs running in FPGA/ASIC accelerators." Work on LLMs is described as "on-going."
This widens the attack surface to natural-language systems deployed on custom hardware: voice assistants, edge reasoning engines, dialogue modules in autonomous vehicles. The attack does not require compromising the training dataset or cloud infrastructure, only access to the chip foundry or supply chain.
The additional power consumption, ~1% for the simple circuit on VGG-16, "a few percent" for the multi-neuron version, generates no measurable anomalies in real deployment contexts where load and temperature variations mask small fluctuations.
Operational Priorities
For security and hardware procurement teams, HAMLOCK imposes three concrete operational priorities. First: treat FPGA/ASIC chips for AI as supply-chain risk components, not as a trusted computing base. Require vendors to provide foundry provenance documentation and, where possible, third-party audits of the physical silicon layout.
Second: integrate reference-chip testing into the pre-deployment validation cycle, comparing model output on known-trusted hardware versus hardware under verification. The source notes that HAMLOCK software alone misclassifies less than 1% of triggered images: a measurable behavior gap between different chips signals an anomaly.
Third: for already-deployed edge models, evaluate the cost-benefit of physical replacement versus risk acceptance, given that fine-tuning and pruning are ineffective. The source documents that retraining can reinforce the trigger: applying post-training techniques without hardware verification is counter-indicated.
The researchers plan to share findings with EDA vendors such as Synopsys and Cadence. Organizations using these tools should monitor updates that integrate anomalous-circuit detection into the design flow.
Frequently Asked Questions
Does HAMLOCK require physical access to the device after deployment?
No. The attack is inserted during chip fabrication. Once manufactured, the device operates normally until it receives the triggered input, with no further compromise needed.
Why isn't validating the downloaded model weights enough?
Because HAMLOCK weights are legitimate in isolation. Misclassification occurs only when the hardware circuits add the bias. Software validation has no visibility into chip behavior.
Is there a practical way to verify the silicon?
The source cites verification of malware "however minute" on fabricated silicon as a defensive direction, but does not document specific techniques or costs. This remains a limitation of the dossier and an open research area.
Information is based on the cited source and current as of publication.
Sources
- https://www.helpnetsecurity.com/2026/06/15/hardware-neural-network-backdoor-research/
- https://img2.helpnetsecurity.com/posts2026/hardware_neural_network_backdoor.webp
- https://unit42.paloaltonetworks.com/ai-agent-supply-chain-risks/
- https://thehackernews.com/2026/06/researchers-build-self-replicating-ai.html
- https://unit42.paloaltonetworks.com/tools/
- https://unit42.paloaltonetworks.com/atoms/
{kind=link}